JKSH
-
Posts
499 -
Joined
-
Last visited
-
Days Won
36
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by JKSH
-
Git detatched head. All of a sudden this makes sense!
JKSH replied to Neil Pate's topic in Source Code Control
🙌 🎉 🎊 🥳 What if you check out a commit that is part of multiple branches at the same time? Indeed. There's not much I can offer that's not already excellently covered by websites like the one you linked. So, I'll offer some fun facts instead: A "remote" repository is usually located on a different machine, which is usually a server. But, the "remote" can also located in a different folder on your local machine. Try it for fun and for education. You usually set your local repository to track a remote repository, which is usually on a server and considered the "authoritative"/"master" copy. But at the same time, that remote repository also could choose to track you -- such that from their POV, your copy of the repository is their "remote". -
Correct, the LabVIEW Python Node currently supports desktop only, not cRIOs. Here is an Idea Exchange post calling for support to be extended to cRIOs: https://forums.ni.com/t5/LabVIEW-Real-Time-Idea-Exchange/Python-Node-support-on-LabVIEW-Realtime-systems/idi-p/3904897?profile.language=en No, that's wrong. In NI Linux RT, VIs can access the entire system (as long as the lvuser account is given the required permissions). It's the LINX Toolkit (for BeagleBone and Raspberry Pi) that puts LabVIEW in a chroot jail. So, although the Python Node isn't available on cRIOs, you can share data between a LabVIEW application and a Python application via inter-process communication (IPC).
-
Wow... I've been scripting that node for years but never noticed that bug. I apply a non-default name to all my return value nodes, but the result is all blank. Someone in NI must have made some "optimizations" since return values of C functions can't have names.
-
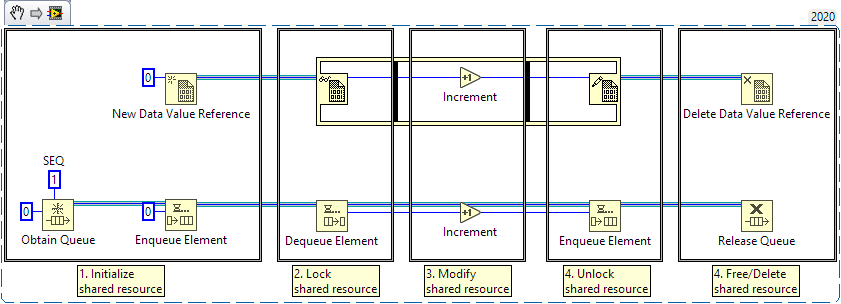
Acknowledged. Nonetheless, I still contend that all of these use-cases are still borderline abuse of the queue API -- @infinitenothing will be fighting an uphill battle trying to explain to text-based programmers why we use SEQs, no matter which use case he picked. It would be cleaner if LabVIEW had proper language constructs for these use cases (even if it's just syntactic sugar that wraps a SEQ behind the scenes)
-
Functionally, dequeueing a SEQ is analogous to reading the DVR in "In Place Element" and analogous to locking a mutex. The 2 LabVIEW code paths above are analogous to this C++ code snippet: // Global variable and mutex std::mutex mtx; int* globalvar = new int; // 1a. Initialize shared resource ("Obtain Queue") int main() { // 1b. Initialize shared resource ("Enqueue Element") *globalvar = 0; // 2. Lock shared resource ("Dequeue Element") mtx.lock(); // 3. Modify shared resource ("Increment") *globalvar += 1; // 4. Unlock shared resource ("Enqueue Element") mtx.unlock(); // 5. Free/Delete shared resource ("Release Queue") delete globalvar; } Notes: It doesn't make much sense to use a global pointer-to-integer in C++; we would just use a global integer directly (or find ways to avoid globals altogether). The code above is to show equivalence to LabVIEW nodes; you'll get funny looks if you present C++ code like this. Using a SEQ like this is unintuitive. Using Queue concepts to share data and lock/unlock access is borderline API abuse. Likewise, using a non-reentrant VI's internal state to act as a global variable (i.e. Functional Globals) is borderline API abuse. Therefore, I would not introduce SEQs and FGVs to newcomers until they are comfortable with other basic concepts of LabVIEW. I would not use them as a starting point for discussions. Nonetheless, we accept/embrace SEQs because they are useful (FGVs are less useful since proper Global Variables exist now). I consider DVRs more intuitive than SEQs, but I prefer SEQs on a block diagram as they don't require the huge rectangular frame.

-
Reentrant: Roughly also "Reentrant", although... LabVIEW VIs are non-reentrant by default, C/C++ functions are reentrant by default. Unlike LabVIEW, there is no setting to force C/C++ functions to become non-reentrant -- you simply code them in a way that makes them reentrant. In LabVIEW, non-reentrant VIs are impossible to run multiple instances simultaneously. In C/C++, non-reentrant functions are unsafe to run multiple instances simultaneously (it's possible; you'll just break things). Single element queue: Depends on how you use it. I often use it as a nicer form of Data Value Reference (see below). Data value reference: "Pointer" (as per the Wiki) or "Reference" Functional global: Doesn't really exist in textual languages. They were invented to fill the role of Global Variables, back in LabVIEW 2 when Global Variables didn't exist. However, an Action Engine (see https://forums.ni.com/t5/LabVIEW/Community-Nugget-4-08-2007-Action-Engines/td-p/503801) roughly maps to a "Singleton". Sounds good to me. However, note that a LabVIEW "variable" is quite different from a textual "variable". A textual variable is more like a LabVIEW wire.
-
TortoiseGit flags changes when LabVIEW diff/compare finds no changes
JKSH replied to PeterB's topic in Source Code Control
One cause is file metadata. For example, VIs store a "Revision Number" which can be different even if the block diagram, front panel, and icon are unchanged. There are probably other causes too, but I don't know what those bytes represent. Pretty often, unfortunately. This is one thing that makes it hard to use source control with LabVIEW. I try to minimize these occurrences by making sure that I don't save a VI unless I've actually modified its contents. P.S. Minor nitpick: It's not that "LabVIEW falsely report differences exist". Rather, LabVIEW causes differences to exist (in the byte sequences of a VI) even when the code is the same. -
That was the PXIe-4844, an optical sensor interrogator. It wasn't just for temperature -- the gratings (microscopic cuts) can measure strain too. It's useful for taking lots of measurements across a long distance with just a single cable (although it was more like ~15 sensors per fiber, not 100), in an intrinsically safe environment, and/or an electrically noisy environment (since the fiber is not affected by noise). $20k was the price of a typical interrogator ~10 years ago. PXIe-4844 was obsoleted because NI exited the market. Other manufacturers are still in it; performance has gone up and price has gone down since then.
-
The license does not specify that you must use a particular installation method. I don't have experience with Gentoo, but I managed to install and run LabVIEW on Ubuntu (Debian-based) by using Alien: https://help.ubuntu.com/community/RPM/AlienHowto I had some issues, however: I couldn't get the Example Finder to work.
-
What license is the code published under?
-
Connecting Arduino to raspberry pi
JKSH replied to mustafa aljumaili's topic in LabVIEW Community Edition
I don't have experience with the TSXperts tools. I do know that for LabVIEW 2020, you can use the NI LabVIEW LINX Toolkit to program Arduinos and Raspberry Pis. -
LabVIEW 2020 and NI LabVIEW LINX Toolkit
JKSH replied to YokohamaTurkey's topic in LabVIEW Community Edition
OP intended to ask about: -
I've used the NI forum to report bugs, and got a few CARs out of that channel. Does that still work? So what happens with customers who have a Development Suite, where a single serial number is used to activate a variety of different products?
-
The .rtexe is actually not an executable file. Rather, it is a "bundle" that contains your compiled VIs. The real executable is /usr/local/natinst/labview/lvrt -- This executable loads your .rtexe bundle and runs the top-level VI(s) from the bundle. The lvrt program checks a config file -- /etc/natinst/share/lvrt.conf -- to find out which .rtexe it should load. So, in theory, you could edit this file and then shut down the VIs that are currently running. This causes lvrt to re-launch, and it will read your updated config file and load your new .rtexe. Notes: Only 1 rtexe can be active at a time. If you simply kill lvrt (as opposed to triggering a proper shutdown from within your .rtexe), LabVIEW thinks that it crashed. By default, LabVIEW will enter Safe Mode after 2 crashes: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z000000kFQ6SAM
-
Related idea: https://forums.ni.com/t5/LabVIEW-Idea-Exchange/Allow-users-to-continue-working-when-a-build-is-in-progress/idi-p/2638771?profile.language=en
-
Communication with hardware using Serial connection (RS232)
JKSH replied to Shaun07's topic in LabVIEW General
Hi, and welcome! These are useful places to start: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA03q000000x1jtCAA https://www.ni.com/en-us/support/documentation/supplemental/06/ni-visa-overview.html -
Is there an "in place" number to string function?
JKSH replied to infinitenothing's topic in LabVIEW General
Not that I know of, but you could use a pre-allocated array of bytes (U8) and replace individual characters with their ordinal values (see https://www.asciitable.com/ -- '1' == 49, '3' == 51) Byte Array to String is a type-cast that doesn't allocate new memory. Of course, if you branch the wire (or keep a copy of the string) and then modify the original byte array, then you'd obviously still need to allocate new memory. May I ask why you need to micro-manage memory usage to this level? -
I'm curious: What are some examples of Win32 API calls that have been most useful in LabVIEW programs?
-
Git delete branch after merging Pull Request
JKSH replied to Neil Pate's topic in Source Code Control
As @pawhan11 said, no story is lost when deleting a branch because only the pointer/reference to a commit is deleted, not the data itself. See here for a visual example: https://github.com/ni/niveristand-fpga-addon-custom-device/network The horizontal lines show the histories of parallel branches. The dots on the horizontal lines represent individual commits. The black-background labels are the "pointers" that represent active branches. "Deleting a branch" means removing a black label. "Creating a branch" means attaching a black label to a commit of your choice. When you are "on a branch" and you make a commit, you add a dot to the commit history chain and move the relevant black label to your new dot. Diagonal arrows show where a branch is merged into another. If you don't delete the branch after merging, then the black label remains on the commit before the merge point. If you delete the branch, the black label disappears. Either way, the branch's commit history is preserved; no story is lost. Mouse over one of the merge commits: You'll see that it's called "Merge branch 'X' into Y", so you can see what the branch was named even if the black label is gone. Note: "master"/"main" is just another branch; there is no separate "trunk" -
That is the only way to add data to the start of a file. This is due to the way filesystems are designed: A file can be easily extended beyond its current end point, but its start point can't be moved. Not to the file itself. However, rather than adding to the start of your file, you could write a simple log viewer app that reads the file and displays the entries on screen in reverse order. Personally, I'm so used to logs having newer entries at the end that I don't expect it the other way. I guess I prefer this out of habit and due to the efficiency of appending data to the end. Having said that, I understand the convenience of having the latest data being visible as soon as the file is opened.
-
Hmm, we don't know which thread(s) are chosen by the CLFN. If it happens to pick the same thread every call, then there will be no ill effects.
-
I'm guessing that the library's functions are not thread-safe. Without forcing the CLFN to use the UI thread, it could use different threads to call the library functions... thus causing a crash.
-
@Aristos Queue You're welcome. Glad I could help. How about storing the elements from "TextIcons.Ignore" in a Set instead of an Array?
-
I do have an implementation of "Split English CamelCase" that handles acronyms: https://github.com/JKSH/LQ-CodeGen/blob/labview-api/src/LabVIEW/Icons and Wires/Name to Icon Lines.vi -- It's based on a shorter regex and currently doesn't handle digits, underscores, or plurals-of-acronyms. I won't be trying to update the icon generator or VI Analyzer within the next 2 months, but someone who wants to try is welcome to use my VI as a starting point.
-
There are some examples and discussions on the NI forum: https://forums.ni.com/t5/Machine-Vision/Using-OpenCV-library-in-LabVIEW/td-p/648429?profile.language=en https://forums.ni.com/t5/LabVIEW/Creating-a-dll-in-Visual-Studio-2015-to-pass-an-image-through/m-p/3334086?profile.language=en