JKSH
-
Posts
499 -
Joined
-
Last visited
-
Days Won
36
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by JKSH
-
Is LabVIEW a programming environment, vs Doom
JKSH replied to Mefistotelis's topic in LabVIEW General
You mean like how a Java compiler prepares only small chunks of code linked together by the JVM? -
I don't understand: Doesn't your test software need to be validated too? And IKVM.NET is a generic wrapper of Java in .NET -- it is not a direct interface for the Bluetooth driver. Why won't this need to be validated? In any case, someone else forked IKVM: https://www.windwardstudios.com/blog/ikvm-is-alive-well
-
There are some examples online about using CANopen in LabVIEW: https://forums.ni.com/t5/Example-Code/CANopen-Reference-Example-for-the-NI-9853-C-Series-CAN-Module/ta-p/3996129?profile.language=en
-
Your last FFT image shows that most of the noise content is in 50 Hz and its harmonics. I'm guessing that you live in a country with 50 Hz mains power, and the electromagnetic radiation is being picked up by your system. You wrote that the system "gives noisy reading even if bias resistors are used" -- Why would you expect the bias resistors to reduce noise? If anything, those long, unshielded resistor leads make them even more sensitive to radiation. Ways to reduce electromagnetic interference include: Using shielded and/or twisted-pair cables. Using shorter cables. Checking your grounding. Your first plot shows huge voltage drops from 1.25 V down to 0.2 V. I'm guessing you have a group loop or short-circuit somewhere in your system when your laptop's power adapter is connected.
-
Best circuit board for LabView
JKSH replied to Ricardo de Abreu's topic in LabVIEW Community Edition
Raspberry Pi and BeagleBone are full-fledged Linux computers. Arduino is a microcontroller. Compare their specifications and I/O to see which one meets your requirements. See also https://forums.ni.com/t5/NI-Blog/LabVIEW-Community-Edition/ba-p/3970512, especially the part about "Hobbyist Hardware". -
Why does "Decimal string to number" break my vim?
JKSH replied to ThomasGutzler's topic in LabVIEW General
Interesting. Looks like there's some type propagation issue when the Decimal String to Number node is combined with the Negate node: Remove the Negate node and the problem disappears. The issue seems to exist in the LV 2020 beta too. Would you like to post in the beta forum, for the attention of NI R&D enginners? http://www.ni.com/support/beta-program/ (I'm happy to post on your behalf, if you prefer)
-
LabVIEW, Websockets, and SVG
JKSH replied to smarlow's topic in Remote Control, Monitoring and the Internet
There are multiple demonstrations in the wild about using WebSocket with LabVIEW. Google should be able to help you. Here is one endorsed by NI: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z000000kJV5SAM @smarlow has not posted in over a year, but might be lurking: https://lavag.org/profile/17965-smarlow/ -
Jim does not come to LAVAG often (e.g. see https://lavag.org/topic/21017-where-are-openg-product-pages-for-packages/?do=findComment&comment=129287 ) I'd imagine you'd get a lot more interest if you post at the JKI forums Nested malleables + VIPC is not a combo that I use
-
LabVIEW NXG uses UTF-8 for all text strings. I think classic LabVIEW (version 20xx) will unlikely ever get full Unicode support.
-
Oops, I just realized: We can't use strcpy() because that would also try to copy the terminating null byte. Use memcpy() instead. (Sorry, my C is rusty)
-
You're welcome Yes. The string bytes must be placed in the memory space immediately after the 4-byte header: (source: http://zone.ni.com/reference/en-XX/help/371361R-01/lvconcepts/how_labview_stores_data_in_memory/) Here's another illustration: A 5-char C string takes 6 bytes of contiguous memory, ending with a null byte: ['H', 'e', 'l', 'l', 'o', 0x00] A 5-char LabVIEW string takes 9 bytes of contiguous memory, starting with a 4-byte integer: [0x05, 0x00, 0x00, 0x00, 'H', 'e', 'l', 'l', 'o'] The LStrHandle cannot hold a pointer to a char array that is held elsewhere.
-
1) LabVIEW manages the memory of the string itself. You must allocate the memory to hold your full string plus a 4-byte header, then copy all of your string data from the DLL memory into LabVIEW memory: LStrHandle cString2LVString(const char *myCString) { const int headerSize = 4; const int stringSize = strlen(myCString); // Allocate memory for the LV string LStrhandle h = (LStrHandle)DSNewHandle(headerSize + stringSize); // Write the LV string header (*h)->cnt = stringSize; // Copy the data into the LV string memcpy( (*h)->str, myCString, stringSize ); return h; } 2) Assuming that you initialized an empty array in LabVIEW and passed the handle into your Call Library Function Node for iir_get_serial_numbers(), typedef struct { int32 len; LStrHandle str[]; } **LStrArrayHandle; int iir_get_serial_numbers(LStrArrayHandle arr) { LStrHandle buffer[1024]; // Make sure this is big enough for all cases, or use // a dynamically-resizing array like a C++ std::vector. int n = 0; while(s_deviceInfo -> next) { buffer[n] = cString2LVString(s_deviceInfo->serial_number); ++n; } // NOTE: At this point, n equals the number of devices // Resize the LabVIEW array const int headerSize = 4; const int arraySize = n*sizeof(LStrHandle); DSSetHandleSize(arr, headerSize+arraySize); // Write the array header (*arr)->len = n; // Copy the string handles into the array for (int i = 0; i < n; ++i) { (*arr)->str[i] = buffer[i]; } return 0; } 3) Yes you can. NOTE: The variable names are different, but from the LabVIEW Manager's point of view an array handle is basically the same thing as a string handle (in Classic LabVIEW, a string is an array of bytes). Allocation, resizing, and data copying techniques are the same for both types of handles. See http://zone.ni.com/reference/en-XX/help/371361R-01/lvconcepts/how_labview_stores_data_in_memory/
-
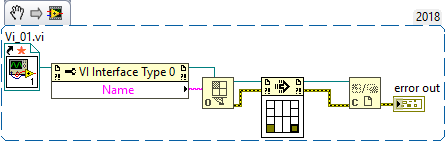
You are calling Open VI Reference using a path that points to your hard drive (D:\DEBUG\debug\vi_01.vi). That VI is not inside your executable. It is possible to make this work, but your executable will break if you move the VI on your hard drive. It is safer to open a strictly-typed Static VI Reference. This loads a copy of Vi_01.vi is stored inside the executable itself: For more info, see https://forums.ni.com/t5/LabVIEW/Static-VI-Reference/td-p/3334006 http://zone.ni.com/reference/en-XX/help/372614J-01/glang/static_vi_ref/
-
Wrapping the queries in a transaction ("BEGIN TRANSACTION" + "END TRANSACTION") could speed things up a lot for 250000 rows
-
Bitbucket sunsetting support for Mercurial
JKSH replied to Francois Normandin's topic in Source Code Control
Files that don't have revisions don't need to be commited into the repository itself. GitHub has a nice feature called GitHub Releases which lets you host "release files" -- it's designed for installers/packages/binaries, but you're free to store other files there too. Each Release is linked to a tag/commit in your Git repo so you know which version of your code was used to generate the installer. Here's an example of some releases from an NI repo: https://github.com/ni/niveristand-scan-engine-ethercat-custom-device/releases/ BitBucket has a lightweight variant of this called BitBucket Downloads (the link is somewhat tangential, but it's the best I could find). I like GitHub's release file hosting more than BitBucket's, but I like BitBucket's issue tracker more than GitHub's. -
Allocating a very large array: out-of-memory without crashing?
JKSH replied to drjdpowell's topic in LabVIEW General
How about creating the initial handle in LabVIEW (e.g. an empty string), passing it into the DLL as a handle, then calling DSSetHandleSize()? -
Poll on Architecture and Frameworks
JKSH replied to drjdpowell's topic in Application Design & Architecture
Sounds like VI Analyzer -
Request for collaboration:Open Tensorflow Toolkit
JKSH replied to Neil Pate's topic in Machine Vision and Imaging
I can't commit to direct collaboration, but I'm happy to share my thoughts, experiences, and code from a similar project. https://www.tensorflow.org/api_docs/ comes with a warning: This means new versions can break backwards compatibility which would be a pain for a non-Python based wrapper/binding project. This is probably a reason why NI might not stick to the latest and greatest version of TensorFlow. I can see 2 possible approaches: Wrap the TensorFlow Python API, and integrate into LabVIEW using the Python Node. Flatten the Tensor C++ API into a C API, wrap the C API, and integrate into LabVIEW using the Call Library Function Node. #1 guarantees that the wrapper won't be broken by a TensorFlow update, but restricts the wrapper to Windows and LabVIEW >= 2018 only. I also don't have experience with the Python Node and don't know what limitations might exist. #2 allows the wrapper to be used on Linux RT and on older versions of LabVIEW, but there's always a risk of compatibility breaks between TensorFlow versions. Also, given the large number of classes and functions (see https://www.tensorflow.org/api_docs/cc ), it might make sense to write a code generator (like VI scripting) that produces the actual wrapper code, instead of writing the wrapper by hand. I've written a code generator to (partially) wrap the C++ API of the Qt toolkit (see https://github.com/JKSH/LQ-CodeGen ). This generator makes many assumptions based on Qt's features and coding conventions so it's not usable for generic C++ libraries, but its source code might provide some ideas and hints. The final wrapper library is at https://github.com/JKSH/LQ-Bindings -
You can create a GitHub-hosted website for an organization: https://pages.github.com/
-
A poor man's way of doing that is to prefix all of the repository names with "OpenG". Users can then use the "search" feature within the Organization to find all repos related to OpenG. For example, https://github.com/ni?q=niveristand vs. https://github.com/ni There's also GitHub Topics, although it crosses organization boundaries: https://help.github.com/en/articles/classifying-your-repository-with-topics e.g. https://github.com/search?q=topic%3Averistand+org%3Ani
-
https://sourceforge.net/projects/opengtoolkit/ @Rolf Kalbermatter has access.
-
I found a post with the exact same error codes: https://forums.ni.com/t5/SystemLink/Package-deployment-failed-through-SystemLink/td-p/3839425 (Google had exactly 1 hit on ni.com) JoshuaP suggests installing ni-certificates first. (His solution is for SystemLink rather than NIPM, so I'm not sure how applicable it is to your case)
-
Neat Humble Bundle: Machinne Learning amd Data Analtics
JKSH replied to Neil Pate's topic in LAVA Lounge
The Humble Monthly is the ongoing subscription. The Humble Book Bundle (and other "Bundles") are once-off payments where you decide how much to pay. -
I can't find any announcement that that NI SoftMotion, CompactRIO, or the NI 9503 will be discontinued. Where did you hear that?
-
Oops, sorry... I didn't notice CL_RenderingDATA. This means the union is 64 bytes long. Try using a cluster of 16 SGLs, and only read the first 3 values. Or, try changing the parameter configuration: Type: Array Data type: 4-byte Single Dimensions: 1 Array format: Array Data Pointer Minimum Size: 16