Leaderboard




Popular Content
Showing content with the highest reputation since 12/04/2017 in all areas
-
After I made this post I decided to bring the LabVIEW Wiki back online. It was not easy and took several days of server upgrades and hacking. The good news is I was able to bring up all the original pages.. The even better news is I talked with @The Q and @hooovahh and we are all on the same page as to how to move forward. @The Q did a great job of stepping forward and trying to fill the void that the LabVIEW Wiki's absence had left. He's agreed to migrate all the new content he created over to the LabVIEW Wiki, from Fandom and continue to develop new articles and content moving forward on the new site. He will also help in moderating the Wiki and will be promoted to Admin rights on the Wiki. His help is much appreciated. The LabVIEW landing page created here on LAVA is awesome but the forums don't lend themselves to static content creation. Instead @hooovahh has agreed to move the old landing page to here. That will be the new home for the landing page. This will become a valuable resource for the community and I hope all of you start pointing new people in that direction. With many editors, it can only get better and better over time. Where do we go from here: Logging in. - The old accounts are still there. If you're a LAVA old-timer, then you can try to login using your LAVA username. If the password doesn't work then reset it. You can also create a new account here. I'm going to announce a day when new accounts can be created. I'm limiting it for now because of all the spam accounts that can be potentially created. There's an issue with the current Captcha system. if you are super-eager to start creating content now and want to help, send me a direct message on LAVA and I can manually create an account right away. - New account creation is now open. Permitted content: - I'm not going to put restrictions on content at the moment. Obvious vandalism or offensive\illegal content will not be tolerated of course. However, the guidelines will be adjusted as time goes on and new content is created. There's just not enough content right now to be overly concerned about this. We need content. Discussions about the Wiki. - Each article page has an associated discussions page where you can discuss issues related to that article. Please use that mechanism (same etiquette as wikipedia). General Wiki issues\questions and high level discussions can be done here. So now, if you need to add content, you can do it yourself. Feedback as always is welcome.20 points
-
Dear Santa NI I am now in my 40s with youngish kids, so despite the fact that all I got for Christmas this year was a Pickle Rick cushion I am not actually complaining. However, I would like to get my order in to the Elves as early as possible. This is my wishlist, in no particular order. I expect this list will not be to everyone's taste, this is ok, this is just my opinion. Make LabVIEW free forever. The war is over, Python has won. If you want to be relevant in 5 to 10 years you need to embrace this. The community edition is a great start but is is probably not enough. Note: I accept it might be necessary to charge for FPGA stuff where I presume you license Xilinx tools. NI is and has always been a hardware company. Make all toolkits free. See the above point. Remove all third party licensing stuff. Nobody makes any money from this anyway. Encourage completely open sharing of code and lead by example. Take all the software engineering knowledge gained during the NXG experiment and start a deep refactor of the current gen IDE. Small changes here please though... we should not have to wait 10 years. Listen to the feedback of your most passionate users during this refactor. NXG failed because you ignored us and just assumed we would consume whatever was placed in front of us. I am talking about the people like those reading this post on Christmas day and their spare time because they are so deeply committed to LabVIEW My eyes are not what they used to be, so please bring in the NXG style vector graphic support so I can adjust the zoom of my block diagram and front panel to suit accordingly As part of the deep refactor, the run-time GUI needs to be modernised. We need proper support for resizable GUIs that react sensible to high DPI environments. Bring the best bits of NXG over to current gen. For example the dockable properties pane. (Sorry not much else comes to mind) Remove support for Linux and Mac and start to prune this cross compatibility from the codebase. I know this is going to get me flamed for eternity from 0.1 % of the users. (You pretty much made this decision for NXG already). Windows 10 is a great OS and has won the war here. Get rid of the 32-bit version and make RT 64-bit compatible. You are a decade overdue here. Add unicode support. I have only needed this a few times, but it is mandatory for a multicultural language in 2021 and going forward Port the Web Module to Current Gen. All the news I have heard is that the Web Module is going to become a standalone product. Please bring this into Current Gen. This has so much potential. Stop adding features for a few years. Spend the engineering effort polishing. Fix the random weirdness we get when deploying to RT Open source as many toolkits as you can. Move the Vision toolkit over to OpenCV and make it open source Sell your hardware a bit cheaper. We love your hardware and the integration with LabVIEW but when you are a big multiple more expensive than a competitor it is very hard to justify the cost. Allow people to source NI hardware through whatever channel makes most sense to them. Currently the rules on hardware purchasing across regions are ridiculous. Bring ni.com into the 21st century. The website is a dinosaur and makes me sad whenever I have to use it Re-engage with universities to inspire the next generation of young engineers and makers. This will be much easier if the price is zero Re-engage with the community of your most passionate supporters. Lately it has felt like there is a black hole when communicating with you Engineer ambitiously? What does this even mean? The people using your products are doing their best, please don't patronise us with this slogan. Take the hard work done in NXG and make VIs into a non-binary format human readable so that we can diff and merge with our choice of SCC tools Remove all hurdles to hand-editing of these files (no more pointless hashes for "protection" of .lvlibs and VIs etc) Openly publish the file formats to allow advanced users to make toolkits. We have some seriously skilled users here who already know how to edit the binary versions! Embrace this, it can only help you. Introduce some kind of virtualenv ala Python. i.e. allow libraries and toolkits to be installed on a per-project basis. (I think this is something JKI are investigating with their new Project Dragon thing) For the love of all that is holy do not integrate Git deeply into LabVIEW. Nobody wants to be locked into someone else's choice of SCC. (That said, I do think everyone should use Git anyway, this is another war that has been won). That is about it for now. All I want is for you guys to succeed so my career of nearly 20 years does not need to be flushed down the toilet like 2020. Love you Neil (Edited: added a few more bullets)16 points
-
The content on this page will go away soon. It's currently being migrated. > New Location < Read about the wiki here This thread is intended to be a place for all things LabVIEW to be able to be found. If you have a resource for LabVIEW feel free to reply with your own content. We are interested in things like person blogs, forums, training information, and anything a user of LabVIEW might want. Several links and sections have been lifted from another resource available over on NI labeled the Content and Communities for LabVIEW Application Development. I'm New To LabVIEW and Need Help Basic Training Information NI Learning Center NI Getting Started -Hardware Basics -MyRIO Project Essentials Guide (lots of good simple circuits with links to youtube demonstrations) -LabVEW Basics -DAQ Application Tutorials -cRIO Developer's Guide Learn NI Training Resource Videos 3 Hour LabVIEW Introduction (Alternate Google Drive) 6 Hour LabVIEW Introduction (Google Drive) Self Paced training for students Self Paced training beginner to advanced, SSP Required Rookie Mistakes in LabVIEW by Digilent State Machine Design Pattern Basic Tutorial Wikipedia Article Sixclear Video Event Driven Design by NI Beyond Basic Training These are topics that are useful but not for those new to LabVIEW or software development. Topics may cover things a novice may have a hard time following. Object Oriented Software Design NI FAQ on Object Oriented Programming Creating Classes When Should you Use Classes Abstraction Abstraction Distraction Introduction to Object Oriented Programming and HAL by Elijah Kerry (Video), Plugin Framework JKI Hardware Abstraction Video Actor Framework Community Introduction Framework Basics Error Handling Basics by NI David Maidman’s Blog Post SOLID Error Handling by Dmitry Structured Error Handler Express VI by NI I Have Questions LAVA Forums - Independent community, with less NI oversight, and generally less new users asking basic questions NI Official Forums - NI's official forum, monitored semi-regularly by NI and the best place to find official support LabVIEW on Reddit - Smaller community but has Reddit features like voting on posts and comments causing interesting topics to get more attention LabVIEW on Stack Overflow - Q&A style community I'm Looking to Find Example Code and Toolkits NI Tools Network - Polished released code distributed as VIPM packages. LAVA Code Repository - Place for Verified, and Unverified code allowing for discussions, in addition to hosting NI Code Exchange / Community Documents - Similar to LAVA but NI's site licensing means less flexibility if you are posting code and want a custom license. NI Reference Designs Portal GitHub - Trending LabVIEW Projects, and All LabVIEW Projects GitLab - LabVIEW Projects BitBucket - LAVA Projects on BitBucket I'm Looking for Blogs There are lots of LabVIEW blogs, covering lots of topics. Some blogs go cold after some time, so below is a table of blogs, highlighting the last post made. At the moment this is updated manually so this will need to be updated periodically. NI's Blog NI's official blog, updated very frequently System Automation Solutions 10/24/2018 Sam Taggart's Blog JKI Blog 9/13/2018 Blog often highlighting JKI's activity including VIPM and other LabVIEW tips DMC Blog - 9/10/2018 LabVIEW category of DMC's official blog Steve Watts Random Ramblings on LabVIEW Design - 10/23/2018 Random Ramblings says it all but often good insight into designs and discussions we don't think about but should question why we use them and how Delacor Blog - 9/4/2018 The Daily CLAD - 9/4/2018 Hooovahh's Blog - 8/24/2018 Brian Hoover's blog focusing on LabVIEW and CAN The LabVIEW Lab - 10/22/2018 Eric Maussion's blog Bloomy's Blog - 8/13/2018 LabVIEW category of Bloomy's official blog Ajay Blog - 10/10/2018 Ajayvignesh's LabVIEW blog Wiresmith - 9/25/2018 James McNally's Blog LabVIEW Craftsmen - 7/3/2018 Wineman Technology Blog - 10/10/2018 LabVIEW category of Wineman's official blog MGI Blog - 6/5/2018 Moore Good Ideas blog Eyes on VIs - 5/25/2018 Christina Rogers blog often focusing on LabVIEW's visual design UI's and UX's QControls - 5/15/2018 Blog series on QControls, and open alternative to XControls Walking The Wires - 5/11/2018 Chirs Roebuck's Blog Not a Tame Lion - 5/5/2016 LabVIEW Artisan - 2/5/2015 Darren Nattinger's LabVIEW blog often highlighting lesser known features of LabVIEW Culverson Software's Blog - 9/20/2014 LabVIEW category of Steve Bird's Blog VI Shots - 7/31/2014 LabVIEW video podcast by Michael Aivaliotis Brian Powell - 12/26/2013 I'm Looking for Videos Similar to blogs, video channels can be hit or miss, and content can become dated. But if you are more of a visual learner these channels offer a chance to learn by watching others. NI Week & CLA Conference - Username: LabVIEW_Videos, Password: LabVIEW GDevCon Conference LabVIEW Architects Forum Delacor's Channel System Automation Solutions LLC Dr. James D Powell NI's LabVIEW Channel LabVIEW ADVANTAGE LabVIEW MakerHub Looking For Certification Help Certification Nugget: CLAD - Certified LabVIEW Associate Developer Certification Nugget: CLD - Certified LabVIEW Developer Certification Nugget: CLA - Certified LabVIEW Architect Connecting With Other LabVIEW Developers User Groups Online communities are a great way to connect and contribute. In addition to online there are Local LabVIEW User Groups which meet regularly to present and understand LabVIEW and NI topics. Find one close you you and subscribe or monitor topics. NI often supports local user groups, but they are in most cases ran and organized by the community. NI Week NI Week is another great way to connect with and learn. Hosted in Austin Texas once a year it is a week long conference with training, discussions, keynotes and other activities. Many previous NI Week videos can be found online but no single source is available which aggregates all marketing, keynotes, and technical sessions in one location. The best resource for content is a site setup for video hosting done by Mark Balla over the years. Summits If you hold a CLA or CLD there are specific summits for you that are free. These are often tailored presentations for a specific skill set with the focus on technical discussion and problem solving. There are two CLA summits, one in Austin Texas, and one in Europe both held once a year. CLD summits happen more frequently and locations change from year to year. Consult their specific discussion forums on NI to see when the next one is. Just like NI Week Mark Balla has several videos available here. Needing Professional Help If a project is getting out of hand and is beyond the skill level of your team, NI suggests looking at one of their Alliance Partners. Contact one in your area, and they will help try to best guide you on your project. I Want To Contribute to the Community Developing Code For Others Arguably the most difficult thing about sharing code, and reusing code, is the mind set and considerations associated with other developers using software you wrote. It is a type of mental exercise where you need to put yourself in the mind of the developer using your software. NI's Reference Deign Portal is a good resource for understanding various coding structures, and best practices for designing code for others, and can help with standardizing code for other developers. TBD (Expect this to be a section on various forums, and code repositories that can be added to along with helping out local user groups, and presenting at NI Week and Summits) Other Important Software Topics Source Code Control (SCC) Recommended SCC for LabVIEW Software Configuration by NI Code Management at Center of Excellence VisualSVN - Free SVN Server Software Delacor Blog with SCC Category -SVN Setup for LabVIEW By Delacor (Video) -Git Setup for LabVIEW By Delacor (Video) SOLID Principals Agile Software Development Principles, Patterns, and Practices (book) How Applying Agile Object-Oriented Design Principles Changes Designs and Code by Dmitry SMoReS development Unit Testing NI Unit Test Group VI Analyzer (Automated Code Inspection) The VI Analyzer is a tool by NI that is included with some versions of LabVIEW and allows for automated inspection of LabVIEW software, to check for various conformity or nonconformity to software practices. The VI Analyzer comes with many useful code checking steps but others can be added. Checkout the VI Analyzer Enthusiasts for more community made tests. LabVIEW Style Checklist Center Of Excellence - Learning VI Analyzer LabVIEW Style Guide Rules to Wire By Part 1 Rules to Wire By Part 2 Virtual Machine Usage TBD16 points
-
I did not know. That possibility was not even on my radar. Even though the drumbeat of bad news had been going for a while, most corporations refuse to change direction on a bad decision. NI showed more sentience than I usually expect from massed humans: the sunk cost fallacy is a trap that is very hard to get out of. I figured the very good engineers on NXG would either surge through it and make it fly or we would bankrupt the company trying. That's the pattern established by plenty of other companies. Mixed. I spent 4.5 years directly working on NXG (2011 to 2016) and countless hours in later years working with the NXG team to design a future G. I really wanted it to fly. There is so much good in that IDE, including some amazing things that I just don't see how we ever do in the LabVIEW codebase without just shattering compatibility. But at the same time, I was watching good friends toil on something that the market just wasn't adopting. The software had some problems that were going to take a long time to solve. The issues were all solvable, but the time needed to fix them... that was harder and harder to justify. NXG gave us a GREAT platform for other software: Veristand, FlexLogger, etc. That code is extremely modular and can be repurposed for all sorts of tools. We also learned a heck of a lot by building NXG -- some things that I thought we could never do in LabVIEW now seem possible. NXG gave us a sandbox to learn a whole lot about modern software engineering without putting the delivery schedule for mature software at risk, and those practices [have been|are being] brought back and applied to LabVIEW -- that will decrease cost of maintaining older code. All in all, NXG was valuable -- the expenditure was not a complete loss. I am very sorry to the few customers who did migrate to NXG. We don't have a reverse migration tool, and building one would be absurdly expensive. Leaving those folks stranded is going to hurt -- I hate letting our customers down and just saying, "We have no solution to help you." There aren't many of those folks (that's essentially the problem), but they do exist, and they are basically stuck having to rewrite their NXG apps in some other tool. I can only hope that they pick LabVIEW. I don't know if this will help us or hurt us with customers in the future... on one hand, people may say, "Well, you let us down on NXG, why should we trust you will be there for us on any new products?" On the other hand, this decision was clearly made listening to customer feedback, and it takes a lot of humility to swallow a loss that big, which may make customers trust our judgement more in the future. And, really, there's nothing to compare with the scale of NXG -- an entire computing platform -- so this does seem like something that needs to be judged in isolation. I really like programming in G. I like being able to expand G to make it more powerful. I wanted NXG to succeed because it had the potential to be a better G. It failed. Its failure means more resources for the existing LabVIEW platform, which will directly help our customers in the short run. It leaves open some big questions for the long run. So, in summary: I think it was a decision that had to be made, and I'm happy to work for a company that can learn from new data, then admit a mistake, and then figure out how to correct it.15 points
-
“There was this fence where we pressed our faces and felt the wind turn warm and held to the fence and forgot who we were or where we came from but dreamed of who we might be and where we might go...” -- Opening lines of “R is for Rocket” by Ray Bradbury I spent 20 years building this G language of ours. It’s time for me to go enjoy the fruits of that labor as a user! I will still be employed by NI, but I will be working full time for Blue Origin. As part of the NI “Engineer in Residence” program, I will be on loan to Blue Origin to revise their engine and support test systems. They wanted a Certified LabVIEW Architect with deep knowledge of LVOOP, multiple years of experience with Actor Framework, and deep knowledge of cRIO and PXI. I asked, “Can we negotiate on that last part?” They said, “Yes, yes we can.” Turns out, based on the interview, I know more than I thought – apparently some hardware knowledge does rub off just by sitting near it for a couple decades. This new job runs for six months, but it is extensible through the end of 2021 at the discretion of myself and Blue Origin. When I come back, I do not know if I will be returning to LabVIEW. Spaceflight has long been a passion of mine. Over my 20 years with LabVIEW R&D, I have had the chance to help out with various Mars rovers, large telescopes, and rocket launches. It has been awesome, and I’m proud of the language advances I brought to LabVIEW that helped so many users along the way. Now, I am going to focus on just one customer for a while... a customer with very large rocket engines! My last day will be Friday, October 23. I will not have the same availability to respond to posts as I have in the past, but Aristos Queue will still be around on the forums. “And, walking, I went beyond the fence.” -- ending of “R is for Rocket”12 points
-
To all things there is a season. Jeff Kodosky helped found National Instruments and invented LabVIEW. He inspired hundreds of us who shapes its code across four decades. But Jeff says it is time to change his focus. Today, NI announced Jeff’s retirement. He will probably always be noodling around on LabVIEW concepts and will remain open to future feature discussions. But his time as a developer is done. Maybe you didn’t know that? Jeff still slings code, from big features to small bugs. He’s been a developer most of the years, happy to have others manage the release and delivery of his software. I spent over two decades working at his side. He taught me to look for what customers needed that they weren’t asking for, to understand what problems they didn’t talk about because they thought the problems were unsolvable. And he built a team culture that made us all collaborators instead of competitors. Thank you, Jeff, for decades of brilliant ideas and staying the course to see those develop into reality. Your work will continue on as one of the key tools on humanity’s expansion to Mars.11 points
-
June 3 will be my last working day at NI. After almost 22 years, I'm stepping away from the company. Why? I found a G programming job in a field I love. Starting June 20, I'm going to be working at SpaceX on ground control for Falcon and Dragon. This news went public with customers at NI Connect this week. I figured I should post to the wider LabVIEW community here on LAVA. I want to thank you all for being amazing customers and letting me participate vicariously in so many cool engineering projects over the years. I'm still going to be a part of the LabVIEW community, but I'm not going to be making quite such an impact on G users going forward... until the day that they start needing developers on Mars -- remote desktop with a multi-minute delay between mouse clicks is such a pain! 🙂11 points
-
How Software Companies Die – Orson Scott Card The environment that nurtures creative programmers kills management and marketing types - and vice versa. Programming is the Great Game. It consumes you, body and soul. When you're caught up in it, nothing else matters. When you emerge into daylight, you might well discover that you're a hundred pounds overweight, your underwear is older than the average first grader, and judging from the number of pizza boxes lying around, it must be spring already. But you don't care, because your program runs, and the code is fast and clever and tight. You won. You're aware that some people think you're a nerd. So what? They're not players. They've never jousted with Windows or gone hand to hand with DOS. To them C++ is a decent grade, almost a B - not a language. They barely exist. Like soldiers or artists, you don't care about the opinions of civilians. You're building something intricate and fine. They'll never understand it. Beekeeping - Here's the secret that every successful software company is based on: You can domesticate programmers the way beekeepers tame bees. You can't exactly communicate with them, but you can get them to swarm in one place and when they're not looking, you can carry off the honey. You keep these bees from stinging by paying them money. More money than they know what to do with. But that's less than you might think. You see, all these programmers keep hearing their fathers' voices in their heads saying "When are you going to join the real world?" All you have to pay them is enough money that they can answer (also in their heads) "Jeez, Dad, I'm making more than you." On average, this is cheap. And you get them to stay in the hive by giving them other coders to swarm with. The only person whose praise matters is another programmer. Less-talented programmers will idolize them; evenly matched ones will challenge and goad one another; and if you want to get a good swarm, you make sure that you have at least one certified genius coder that they can all look up to, even if he glances at other people's code only long enough to sneer at it. He's a Player, thinks the junior programmer. He looked at my code. That is enough. If a software company provides such a hive, the coders will give up sleep, love, health, and clean laundry, while the company keeps the bulk of the money. Out of Control - Here's the problem that ends up killing company after company. All successful software companies had, as their dominant personality, a leader who nurtured programmers. But no company can keep such a leader forever. Either he cashes out, or he brings in management types who end up driving him out, or he changes and becomes a management type himself. One way or another, marketers get control. But...control of what? Instead of finding assembly lines of productive workers, they quickly discover that their product is produced by utterly unpredictable, uncooperative, disobedient, and worst of all, unattractive people who resist all attempts at management. Put them on a time clock, dress them in suits, and they become sullen and start sabotaging the product. Worst of all, you can sense that they are making fun of you with every word they say. Smoked Out - The shock is greater for the coder, though. He suddenly finds that alien creatures control his life. Meetings, Schedules, Reports. And now someone demands that he PLAN all his programming and then stick to the plan, never improving, never tweaking, and never, never touching some other team's code. The lousy young programmer who once worshiped him is now his tyrannical boss, a position he got because he played golf with some sphincter in a suit. The hive has been ruined. The best coders leave. And the marketers, comfortable now because they're surrounded by power neckties and they have things under control, are baffled that each new iteration of their software loses market share as the code bloats and the bugs proliferate. Got to get some better packaging. Yeah, that's it. Originally from Windows Sources: The Magazine for Windows Experts, March 199511 points
-
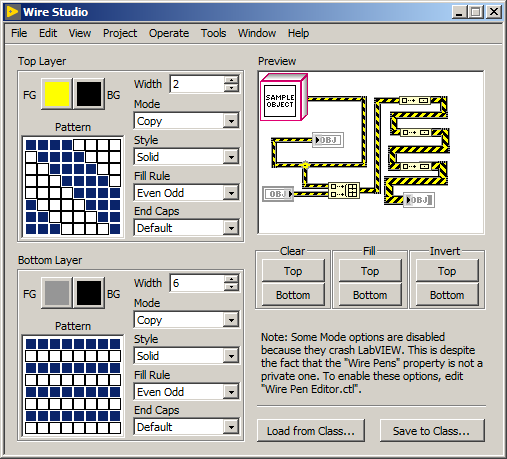
You know how you can change the wire appearance for a class in the class properties? As it turns out, LabVIEW internally allows for more flexibility than that dialog gives you. So I made an advanced wire editing tool...and unlike a lot of stuff I post, you can actually use this for serious projects, because it does not use any private/unsupported LabVIEW functionality! With this tool, you can set wire size without limits (with results similar to this), customize both wire layers with any 8x8 monochrome pattern, and also mess with different draw options. Strangely, a few of these settings seem to have no effect, and many of the options for one of them actually crash LabVIEW. (These ones are disabled in my tool, but you can re-enable them by editing a typedef.) Given that this is actually a documented, supported property that's officially supposed to work, I've reported this as a bug to NI; if any NI engineers see this and feel like investigating, you can refer to service request #7762024. Latest version: Wire Studio 2.zip Old versions: Revision 1
 11 points
11 points -
Update to this post: My sabbatical has ended. I went from Blue Origin to Microsoft, but as of a couple weeks ago, I have now returned to LabVIEW development. At some point, I may put together a public summary of my experiences as a full-time G dev. For now, be assured that I am feeding that experience back into the feature backlog priority list!10 points
-
TDF team is proud to propose for free download the scikit-learn library adapted for LabVIEW in open source. LabVIEW developer can now use our library for free as simple and efficient tools for predictive data analysis, accessible to everybody, and reusable in various contexts. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy from the famous scikit-learn Python library. Coming soon, our team is working on the « HAIBAL Project », deep learning library written in native LabVIEW, full compatible CUDA and NI FPGA. But why deprive ourselves of the power of ALL the FPGA boards ? No reason, that's why we are working on our own compilator to make HAIBAL full compatible with all Xilinx and Intel Altera FPGA boards. HAIBAL will propose more than 100 different layers, 22 initialisators, 15 activation type, 7 optimizors, 17 looses. As we like AI Facebook and Google products, we will of course make HAIBAL natively full compatible with PyTorch and Keras. Sources are available now on our GitHub for free : https://www.technologies-france.com/?page_id=4879 points
-
Nice! While you are there please convince Elon to buy NI and turn it back into an engineering company 🤣9 points
-
he information formally listed in this thread is no longer valid. The site is now offline. All the videos have been moved to dedicated event pages on the LabVIEW Wiki. https://labviewwiki.org/wiki/Events - LabVIEW Wiki https://www.youtube.com/channel/UCUiBucUImKZERoTzaOtHB5g/featured - Youtube Channel9 points
-
So I wasn't there but there was a public announcement at GDevCon about a new edition of LabVIEW called Community Edition which is the LabVIEW Professional version (I read that as application builder included), and completely free with no watermarks for non-commercial use. NI hasn't made any post about timelines, or other details yet but I hear those are in the works. This is obviously a huge thing for LabVIEW as any monetary barrier to entry will discourage new developers from experimenting with LabVIEW. And then there is the fact that those that are familiar with LabVIEW, can keep up with the newest version outside of their company, or when they are between jobs.9 points
-
Hey folks. this year we're trying something new. All Videos for NIWeek 2019 can be found here: https://labviewwiki.org/wiki/NIWeek_2019 Feedback welcome. Thanks to @Mark Balla and other volunteers for recording the videos. Edit: We're starting to add the back catalog to YouTube. NIWeek 2018 videos are also up.9 points
-
Version 1.5.4
1,056 downloads
Package for working with JSON. Uses high-speed text parsing, rather than building an intermediate representation as with prior LabVIEW JSON libraries (this is much faster). Allows easy working with "subitems" in JSON format, or one can convert to/from LabVIEW types. Uses the new "malleable VIs" of LabVIEW 2017 to convert to any LabVIEW type directly. JSON text makes use of a form a JSON Path notation, allowing easy and rapid access to the subitems of interest. Requires LabVIEW 2017 and install by VIPM 2017 or later. Original conversation about JSONtext. On the LabVIEW Tools Network. JDP Science Tools group on NI.com. Copyright 2017 JDP Science Limited8 points -
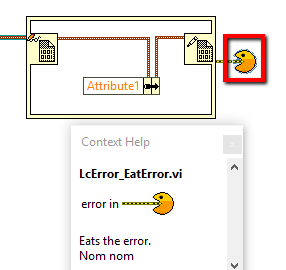
This is how I clear errors.
8 points
-
Hello all. The last 72 hours we've had some issues with spam bots taking over the forums, pretty aggressively. As a result new account creation has been temporarily disabled. Thanks to all those using the report feature. I don't read every post but I do read every new thread title and you are very helpful in spotting issues. There might be some forum upgrades taking place soon to help combat this issue. After which the new user creation will be turned back on. Nothing is scheduled yet but this is meant to be a heads up that the forums might have some down time soon and it is to be expected. Thanks for your patients.7 points
-
Hello. I am not a bot... I'm planning on taking the site offline this weekend to perform long overdue upgrades and to investigate ways to curb the spam attacks. Thanks to everyone for all the help cleaning up the forums. Hopefully I can find a solution and we can get back to the usual next week.7 points
-
I'm excited to release ViPER ViPER is an Object Oriented design Framework that supports dependency injection and recursive object creation. Systems are assembled at runtime from a collection of pre-built components defined by an Object Definition Document. Please visit the project on GitHub https://github.com/kurtafriday/ViPER I've presented this framework at several GLA Conferences, for an overview and guidance please view. GLA 2021 https://labviewwiki.org/wiki/GLA_Summit_2021/Open_Source_ViPER GLA 2020 https://labviewwiki.org/wiki/GLA_Summit_2020/ViPER_-_A_LabVIEW_Dependency_Injection_Framework This branch of ViPER has been used by us to develop systems in regulated industries for several years, it's solid and reliable, however its windows only. I'm working on ViPER_WinRT which is compatible with Windows and RT and we have already used it for several systems. I'll be releasing ViPER_WinRT in the coming months. I'll work to get ViPER onto the VIPM Tools Network soon. I'm looking forward to the feedback and I hope you enjoy and get value from this framework. Ping me if you have any questions. kurt@medulla.net7 points
-
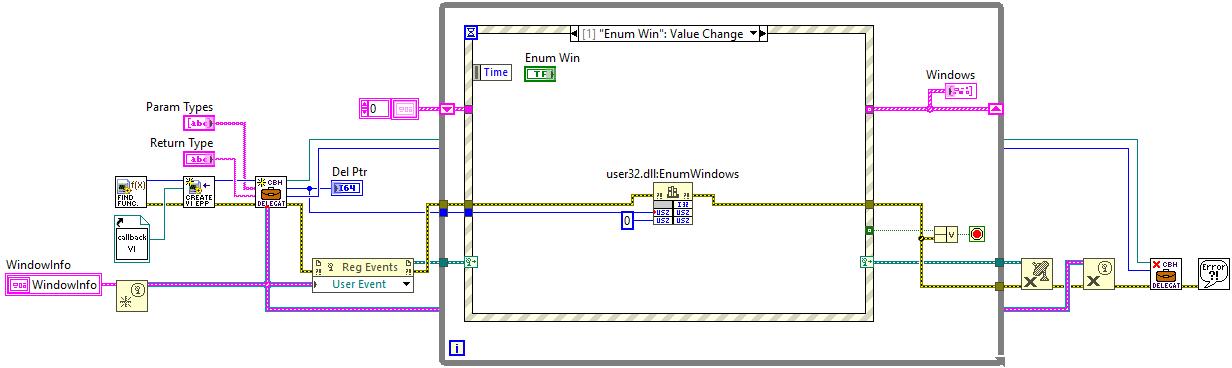
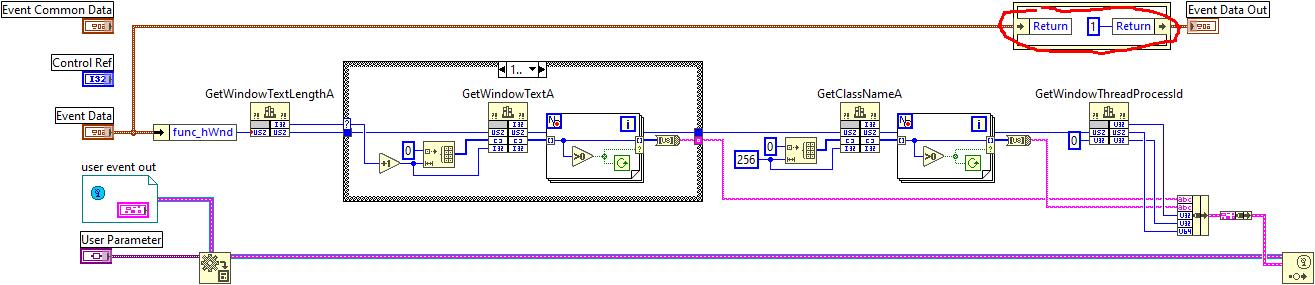
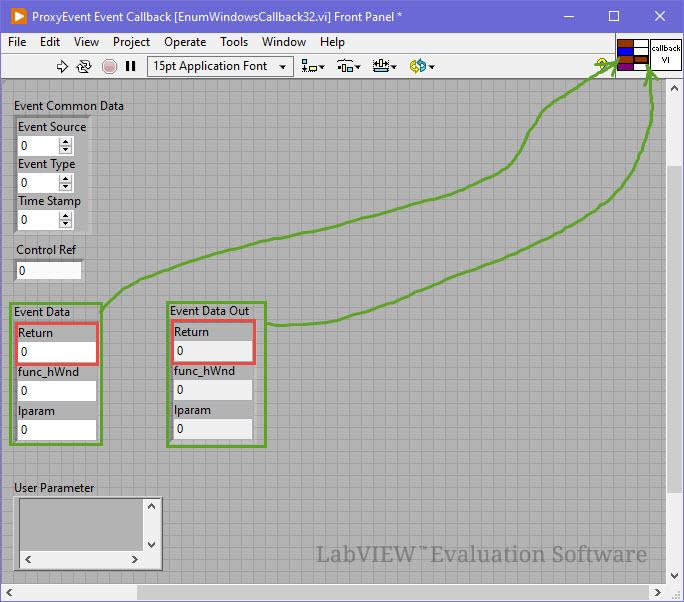
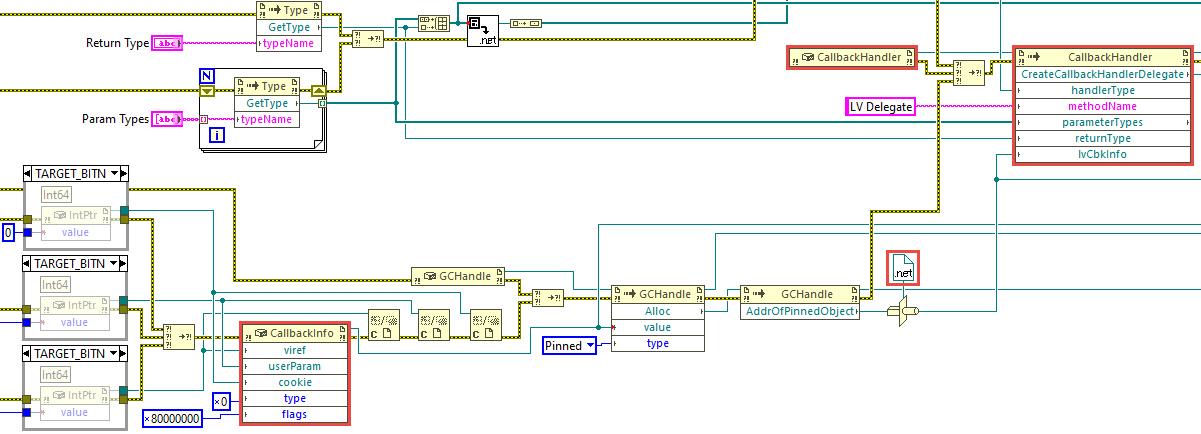
Usual disclaimer. Method described below is strictly experimental and not recommended to use in real production. N.B. This is based on .NET, therefore Windows only. This text is sorta lengthy, but no good TL;DR was invented. You may scroll down to the example, if you don't want to read it all. One day I was stalking around NI forums and looking at how folks implement their callback libraries to call them from LabVIEW. After some time I came across something interesting: How to deal with the callback when I invoke a C++ dll using CLF? There someone has figured out how to make LabVIEW give us a .NET delegate using a dummy event. This technique is different from classic way of interfacing to callbacks, because it allows to implement the callback logic inside a VI (not inside a DLL), but still it requires writing some small assembly to export the event. Even though Rolf said there that it's not elegant, I decided to study these samples better. Well, it was, yeah, simple (no wonder it was called SimpleProxy/SimpleDemo/SimpleCallBack) and very instructive at the same time. It worked very well in both 32- and 64-bit LabVIEW, so I had fun to play around and learn some new things about .NET events and C#. After all I started to think, whether we really need this dummy assembly to obtain a delegate... Initially I was looking for a way to create a .NET event at the run-time with Reflection.Emit or with Expression Trees or somehow else, but after googling for few days and trying many things in both C# and F# I came to a conclusion that it's impossible. One just can create event handlers and attach them to already existing events, not create events on their own. Okay. First I decided to know how exactly LV native Register Event Callback node works. Looking ahead I'll say it was a dead end, but interesting. Ok, the Register Event Callback node in fact consists of two internal functions - DynEventAllocRegInfo and DynEventRegister - with the RegInfo structure filling between them. The first one creates and returns a new RegInfo with a Reg Event Callback reference, the second one actually registers the RegInfo and the reference in the VI Data Space (the prototypes and the struct fields are more or less figured out). But when I started to play with the CLFN's to replace the Register Event Callback node, I ran into few pitfalls. To work properly the DynEventRegister function needs one of the RegInfo's fields to be a type index of (hidden) upper left terminal of the Constructor node. This index is stored in the VI's Data Space Type Map (DSTM) and determined at the compile time. I did not find a reliable way to pull it out of the DSTM. Moreover the RegInfo struct doesn't have a field for the VI Entry Point or anything like that. Instead LabVIEW stores the EP in some internal tables and it's rather complicated to get it from there. For these reasons I have given up studying the Register Event Callback node. Second I turned my attention to the delegate call by its pointer. I soon found out that LabVIEW generates some middle layer (by means of .NET) to convert the parameters and other stuff of the native call to the VI call. That conversion was performed by NationalInstruments.LabVIEW###.dll in the resource folder (a hidden gem!). This assembly has almost everything that we need: the CallbackInfo and CallbackHandler classes, and the latter has two nice methods: CallLabView and CreateCallbackHandlerDelegate. Referring to the SimpleDemo/SimpleCallBack example, when we call the delegate by its pointer, LabVIEW calls this chain: CallLabView -> EventCallbackVICall internal function -> VI EP. All that was left to do was to try it on the diagram with .NET nodes, but... there was another obstacle. Sure that you'll connect the inputs right? You will not. These parameters are not what they seem (at least, one of them). The viref is not a VI reference, but a VI Entry Point pointer. It's not a classic function EP pointer, but a pointer to a LabVIEW internal struct, which eases the VI calls (it's called "Vepp" in the debug info). The userParam is a pointer to the User Parameter as for the Register Event Callback node. The cookie is a pointer to the .NET object refnum from the Constructor node (luckily NULL can be passed). And the type and flags are 0 and 0x80000000 for standard .NET callbacks. Now how and where could we get that VI EPP? Good question. There is a function inside LabVIEW, that receives a VI ref and returns an allocated VI EPP. But sadly it's not exported at all. Of course, this ain't stoppin' us. I used a technique to find the function by a string constant reference in the memory of a process. It's known to be not very reliable between different versions of the application, therefore many tests were made on many versions of LabVIEW. After finding the function address, it's possible to call it using this method (kind of a hack as well, so beware). Is this all enough to run .NET nodes now? For the CallLabView yes. It's simplier than CreateCallbackHandlerDelegate, but doesn't provide a delegate. It passes the parameters to the VI, calls it and returns. The return and parameters could be utilized onwards, of course, but nothing more. To obtain a delegate it's necessary to call the CreateCallbackHandlerDelegate. This method wants the handlerType input wired and to be valid in .NET terms, so proper type must be made. Initially I tried to use .NET native generic delegates: Action, Predicate and Func. Everything went fine except the GetFunctionPointerForDelegate, which didn't want to work with such delegates and complained. The solution was in applying some obscure MakeNewCustomDelegate method as proposed here. Now the GetFunctionPointerForDelegate was happy to provide a pointer to the delegate and I successfully called the callback VI both "manually" and by means of Windows API. So finally the troubles were over, so I could wrap everything into SubVI's and make a basic example. I chose EnumWindows function from WinAPI, because it's first that came to my mind (not the best choice as I think now). It's a simple function: it's called once with a callback pointer and then it starts looping through OS windows, calling a callback on each iteration and passing a HWND to it. This is top-level diagram of the example: I won't be showing the SubVI's diagrams here as they are rather bulky. You may take a look at them on your own. I'll make one exception though - this is the BD of the callback VI. As you could know, EnumWindowsProc function must return TRUE (1) to continue windows enumeration. How do we return something from a callback VI? Well, it's vaguely described here, I clearly focus on this. You must supply first parameter as a return value in both Event Data clusters and assign these two to the conpane. On the diagram you set the return as you need. These are the versions on which I tested this example (from top to bottom). Some nuances do exist, but generally everything works well. LabVIEW 2023 Q3 32 & 64 (IDE & RTE) LabVIEW 2022 Q3 32 & 64 (IDE & RTE) LabVIEW 2021 32 & 64 (IDE & RTE) LabVIEW 2020 32 & 64 (IDE & RTE) LabVIEW 2019 32 & 64 (IDE & RTE) // 32b - on one machine RTE worked only w/ "Allow future versions of the LabVIEW Runtime to run this application" disabled (?), 64b - OK LabVIEW 2018 32 & 64 (IDE & RTE) LabVIEW 2017 32 & 64 (IDE & RTE) // CallbackInfo& lvCbkInfo, not ptr LabVIEW 2016 32 & 64 (IDE & RTE) // same LabVIEW 2015 32 & 64 (IDE & RTE) // same LabVIEW 2014 32 & 64 (IDE & RTE) // same LabVIEW 2013 SP1 32 & 64 (IDE & RTE) // same + another string ref + 64b: "lea r8" (4C 8D 05) instead of "lea rdx" (48 8D 15) LabVIEW 2013 32 & 64 (IDE & RTE) // same + no ReleaseEntryPointForCallback, CreateCallbackHandler instead of CreateCallbackHandlerDelegate LabVIEW 2012 32 & 64 (IDE & RTE) // same + forced .NET 4.0 LabVIEW 2011 32 & 64 (IDE & RTE) // same LabVIEW 2010 32 & 64 (IDE & RTE) // same LabVIEW 2009 32 & 64 (IDE & RTE) // same EnumWindows (LV2013).rar EnumWindows (LV2009).rar How to run: Select the appropriate archive according to your LV version: for LV 2013 SP1 and above download "2013" archive, for LV 2009 to 2013 download "2009" archive. Open EnumWindows32.vi or EnumWindows64.vi according to the bitness of your LV. When opened LV will probably ask for NationalInstruments.LabVIEW###.dll location - point to it going to the resource folder of your LV. Next open Create Callback Handler Delegate.vi diagram (has a suitcase icon) and explicitly choose/load NationalInstruments.LabVIEW###.dll for these nodes marked red: It's only required once as long as you stay on the same LV version. For the constant it may be easier to create a fresh one with RMB click on the lvCbkInfo terminal and choosing "Create Constant" entry. Now save everything and you're ready to run the main VI. Remarks / cons: no magic wand for you as for the Register Event Callback node, you create a callback VI on your own; the parameters and their types must be in clear correspondence to those of the delegate; obviously .NET callbacks are X times slower than pure C/C++ (or any other unmanaged code) DLL; search for CreateVIEntryPoint function address takes time (about several seconds usually); on 64 bits it lasts longer due to indirect ref addressing; no good way to deallocate VI EPP's; the ReleaseEntryPointForCallback function destroys AppDomain when called (after such a call the VI must be reopened to get .NET working) - usually not a problem for EXE's. Conclusion. Although it's a kind of miracle to see a callback VI called from 'outside', I doubt I will use it anywhere except home. Besides its slowness it involves so many hacks on all possible levels (WinAPI, .NET, LabVIEW) that it's simply dangerous to push such an application to real life. Likely this thread is more of a detailed reference for the future idea in NI Idea Exchange section.
7 points
-
I've been surprised today with one of the LabVIEW's most useful functions (imo) which I use all the time. After so many years and only now seeing this behavior/feature. I thought I share it 🙂 I've always used an empty array of N-Dim for my desired type input. only to accidently find out today that I can also use a scalar for the type. ha!
7 points
-
The core of our business has changed. Fewer users are developing their own test applications; instead, they're buying something off the shelf like TestStand. Fewer users are developing their own data acquisition software; instead, they're buying something off the shelf like FlexLogger. This trend alters significantly the role of LabVIEW (CG and NXG) in the NI ecosystem -- it becomes far less important to support whole application development (though, of course, we still do and will) and far more important to support "just a bit of customization" when the pre-built tools fail. A lot of software has an endless array of switches and options, but LV provides the ability for a user to write a custom routine to specify the behavior they want in some corner niche of a product. Think like Signal Express, able to generate sine wave, square wave, triangle wave or "pick a VI that generates the wave that you need" wave. What's funny about this is that although the app devs are growing rarer, they're also individually growing more profitable for NI as a whole because the companies still paying to develop custom software are the ones that are generally buying a lot of hardware to do something unique in the world (or not in the world, in the case of SpaceX, Blue Origin, Ad Astra, etc.). So I don't expect the big scale parts of LabVIEW to vanish, but I do expect them to be driven by specific requests from megascale customers rather than from the massed collective. The massed collective will be driving more of the IDE developments. At least, that's my suspicion at this time based on the presentations I've seen.7 points
-
The New Data Value Ref and Delete Data Value Ref nodes will be able to be in inline VIs (and thus malleable VIs) in LV 2020.7 points
-
I've exported the OpenG sources from Sourceforge SVN to Github. It's located here: https://github.com/Open-G I'm hoping this will encourage collaboration and modernization of the OpenG project. Pull requests are a thing with Git, so contributions can be encouraged and actually used instead of dying on the vine.7 points
-
Greetings Friends of LAVA, colleagues, cohorts, and Wireworkers Extraordinaire -- it's LAVA BBQ time! Date: Tuesday, May 21, 2019 Time: 7:30-10:00 pm Location: Uncle Billy's Brewery and Smokehouse, 1530 Barton Springs Rd, Austin, TX 78704 (1.5 miles from Convention Center) Cost: $25 Early Bird (through April 30th) $30 Regular Admission (through May 20th) $35 Door Price (May 21st) Meal Options: Expect to enjoy your choice of meats (brisket, turkey, ribs) with sides like street corn, cole slaw, and bbq beans. A vegetarian option is available when purchasing tickets. Cash beer bar. Who: Everyone is welcome, including spouses traveling with you. Even if it's your first time, expect to recognize many faces/names from the forums and NI R&D. What to wear: It's a covered, outdoor venue in Austin during Spring, so dress for the weather and comfort. Door Prizes: We will have a drawing to give away prizes. All attendees are eligible and will receive a door prize ticket upon entry. See below about sponsoring a door prize yourself to share the love. Hope to see you there! Chime in once you buy tickets to let everyone know you're coming. ------------>>------------>> Get LAVA BBQ 2019 Tickets Here <<------------<<------------ The venue is a 30 minute walk from the convention center, or a $6 Uber. Get together and carpool, people are typically gathering at Challenge the Champions in the Expo Hall, which is great fun. There is a free parking garage behind the building. We'd love for you to sponsor a door prize - Continue Reading: If you or your company want to sponsor a LAVA BBQ door prize, please post a reply below. You can also include a small blurb about your company and a link to your website in the post below. By donating a prize you and your company will receive a small announcement of your choosing, during the event. We will ask you to write the announcement on a post-it note and will attach it to the prize to be read before awarding it. We love the door prizes, but we love time for socializing too. Here are some guidelines to keep our event balanced and streamlined. Single item donations work best. If donating more than one item, then multiple identical items is strongly preferred. If donating non-tangible items or something that is not physically with you, then please bring a card with your contact info and instructions on how to collect the prize. This will be given to the winner. Donations are typically $25-$200 in value. Not recommended: Apparel (hats, t-shirts, underwear, etc.) - never the right size Software licenses (Toolkits, add-ons, LabVIEW) Branded trade show booth type giveaways (mouse pads, pens, keychains, etc.) Jokes or something meant as a gag and not a real prize7 points
-
We'll grow into it eventually 😋
7 points
-
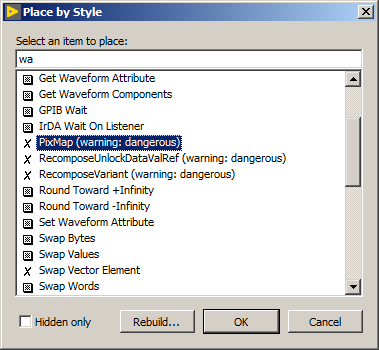
There are a bunch of objects in LabVIEW that aren't exposed in the default palettes, and are normally inaccessible except through scripting. I made a Quick Drop plugin that exposes all of these. Many of these are no longer supported, and others never were supported in the first place. Hidden ones are displayed with an "X" next to them to warn you: as I often say, be careful with these, and don't use them in any code you care about, as they can cause crashes, data corruption, and who knows what else! Download the LLB below and place it in your <LabVIEW install dir>\resource\dialog\QuickDrop\plugins folder. Then press Ctrl+Space, Ctrl+S to open this dialog. Select an item from the list and click OK, and there you go. There's some interesting/strange stuff in here! EDIT: Couple things I forgot to mention. The first time you open this (and whenever you rebuild the list) it uses two private properties on the app reference, to get the list of controls and indicators in the palette. Since this is just a property read, I'm sure the worst that could happen is a crash when you try to open the dialog, but I can't make any guarantees. Also there's some false positives for hidden items, mainly with front panel controls/indicators that come in different styles. Place by Style.llb
7 points
-
Greetings Friends of LAVA, colleagues, cohorts, and Wireworkers Extraordinaire -- it's LAVA BBQ time! Change log for 2018: Prices have been rolled back to a previous, cheaper version New location, see below Date: Tuesday, May 22, 2018 Time: 7:30-10:00 pm Location: Uncle Billy's Brewery and Smokehouse, 1530 Barton Springs Rd, Austin, TX 78704 (1.5 miles from Convention Center) Cost: $25 Early Bird (through May 4th) $30 Regular Admission (through May 20th) $35 At the door (May 21st - 22nd) Meal Options: Expect to enjoy your choice of meats (brisket, turkey, ribs) with sides like mac and cheese, cole slaw, and potato salad. A vegetarian option is available when purchasing tickets. Cash beer bar. Who: Everyone is welcome, including spouses traveling with you. Even if it's your first time, expect to recognize many faces/names from the forums and NI R&D. What to wear: It's a covered, outdoor venue in Austin during Spring, so dress for the weather and comfort. Door Prizes: We will have a drawing to give away prizes. All attendees are eligible and will receive a door prize ticket upon entry. See below about sponsoring a door prize yourself to share the love. ------------>>------------>> Get LAVA BBQ 2018 Tickets Here <<------------<<------------ The venue is now a 30 minute walk from the convention center, or a $6 Uber. Get together and carpool, people are typically gathering at Challenge the Champions in Exhibit Hall 4, which is great fun. There is a free parking garage behind the building. We'd love for you to sponsor a door prize - Continue Reading: If you or your company want to sponsor a LAVA BBQ door prize, please post a reply below. You can also include a small blurb about your company and a link to your website in the post below. By donating a prize you and your company will receive a small announcement of your choosing, during the event. We will ask you to write the announcement on a post-it note and will attach it to the prize to be read before awarding it. We love the door prizes, but we love time for socializing too. Here are some guidelines to keep our event balanced and streamlined. Single item donations work best. If donating more than one item, then multiple identical items is strongly preferred. If donating non-tangible items or something that is not physically with you, then please bring a card with your contact info and instructions on how to collect the prize. This will be given to the winner. Donations are typically $25-$200 in value. Not recommended: Apparel (hats, t-shirts, underwear, etc.) - never the right size Software licenses (Toolkits, add-ons, LabVIEW) Branded trade show booth type giveaways (mouse pads, pens, keychains, etc.) Jokes or something meant as a gag and not a real prize Hope to see you there! Chime in once you buy tickets to let everyone know you're coming.7 points
-
I just became aware of this thread and I'm not going to go back and comment on all the discussion points that have been made before, except to say: The original code which did not use a shift register was wrong, but happened the work because of a bug in the LabVIEW inplaceness algorithm. Any input tunnel should retain its original value of every iteration of the loop, so it should've stayed not-a-refnum every time, and therefore the dynamic registration should should have been lost where the loop iterated. The issue was that the left dynamic registration terminal (which is always in-place to the right one) was also in-place to the input tunnel, causing its value to be stomped incorrectly. This is clearly a bug and needed to be fixed. It violated dataflow 'rules' for how tunnels are supposed to behave, and could've made some correct programs yield incorrect behavior. This is not a change that would break a correctly written program, so it does not qualify as an "API breaking" change; this usage has always been wrong but happened to work due to a bug. (This is categorically different than changing behavior of correct code or even changing undocumented behavior, which we try strenuously to avoid.)7 points
-
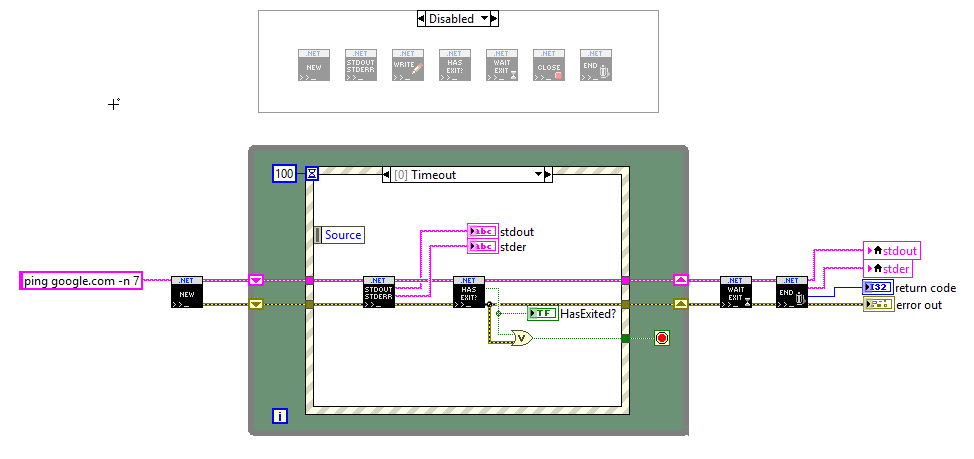
I threw this together, and maybe someone will find it useful. I needed to be able to interact with cmd.exe a bit more than the native system exec.vi primitive offers. I used .NET to get the job done. Some notable capabilities: - User can see standard output and standard error in real-time - User can write a command to standard input - User can query if the process has completed - User can abort the process by sending a ctrl-C command Aborting the process was the trickiest part. I found a solution at the following article: http://stanislavs.org/stopping-command-line-applications-programatically-with-ctrl-c-events-from-net/#comment-2880 The ping demo illustrates this capability. In order to abort ping.exe from the command-line, the user needs to send a ctrl-c command. We achieve this by invoking KERNEL32 to attach a console to the process ID and then sending a ctrl-C command to the process. This is a clean solution that safely aborts ping.exe. The best part about this solution is that it doesn't require for any console prompts to be visible. An alternate solution was to start the cmd.exe process with a visible window, and then to issue a MainWindowClose command, but this required for a window to be visible. I put this code together to allow for me to better interact with HandbrakeCLI and FFMPEG. Enjoi NET_Proc.zip
6 points
-
The conference went well. We got lots of good video, but it will take a while to edit. I don't have an exact timeframe, but they should be posted within the next month or so. We had an extra cameraman and better lighting and angles this year, so the videos should be even better than last year.6 points
-
Hello everybody! During a few last years I received multiple appeals to release AES library that I developed in 2011 into open-source. So, I've just done exactly this: https://github.com/IgorTitov/LabVIEW-Advanced-Encryption-Standard I released it under MIT license (which means that there are no restrictions whatsoever). No VI passwords, no uglification. LabVIEWishly Yours, Igor Titov.6 points
-
View File Hooovahh's Tremendous TDMS Toolkit This toolkit combines a variety of TDMS functions and tools into a single package. The initial release has a variety of features: - Classes for Circular, Periodic, Size, and Time of Day TDMS generation with examples of using each - Reading and Writing Clusters into TDMS Channels - XLSX Conversion example - File operations for combining files, renaming, moving, and saving in memory to zip - Basic function for splitting TDMS file into segments (useful for corrupt files) - Reorder TDMS Channel with Demo There is plenty of room for improvements but I wanted to get this out there and gauge interests. The variety of classes for doing things, along with VIMs, and class adaptation makes for using them easier. If I get time I plan on making some blog posts explaining some of the benefits of TDMS, along with best practices. Here is a youtube video demonstration of some of the features of this toolkit. Submitter hooovahh Submitted 12/12/2019 Category *Uncertified* LabVIEW Version 2018 License Type BSD (Most common)6 points
-
I suggest LabdejaVIEW...6 points
-
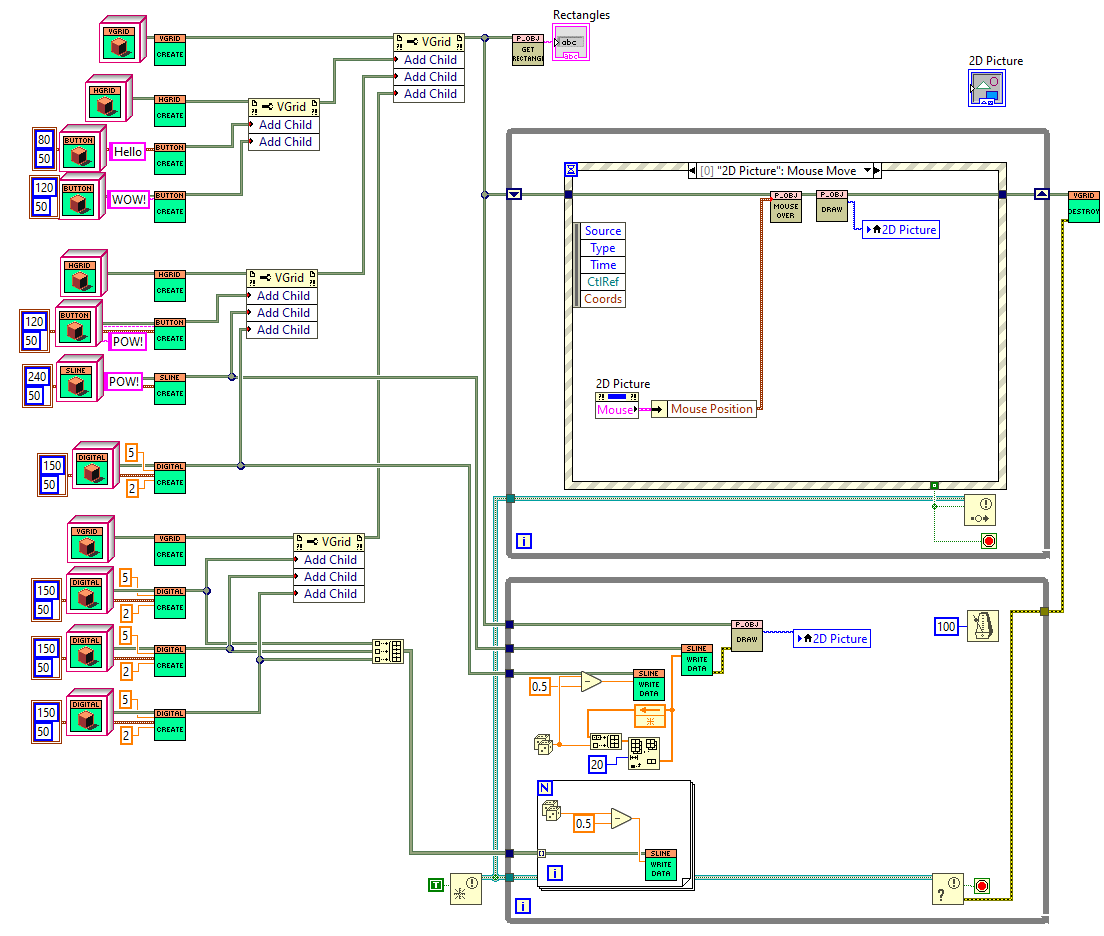
Two questions about this: 1. Does something like this already exist? 2. Is this something that could be useful? Every once in a while I need dynamic UI components that can be generated at runtime. One nice thing to use for this is a picture control; however it doesn't lend itself as well to keeping other pieces of function such as mouse click events and such. I put together a mini library of UI functions for this that has the ability to be extended. The UI can be generated dynamically at runtime and be any picture thing that you can draw. Using Standard layout techniques that you might find in other GUI libraries. The hierarchy generation can always be simplified by using some type of templating string. Example1.vi Front Panel on Pgui2.lvproj_My Computer _ 2021-07-02 14-03-54.mp4
6 points
-
Does it help to re-ask the question as "where should LabVIEW have a future?" It is not difficult to name a number of capabilities (some already stated here) that are extremely useful to anyone collecting or analyzing data that are either unique, or much simpler, using LabVIEW. They're often taken for granted and we forget how significant they are and how much power they unlock. For example (and others can add more): FPGA - much easier than any text-based FPGA programming, and so powerful to have deterministic computational access to the raw data stream Machine vision - especially combined with a card like the 1473R, though it's falling behind without CoaXPress Units - yes no-one uses them , but they can extend strict programming to validation of correct algorithm implementation Parallel and multi-threaded programming - is there any language as simple for constructing parallel code? Not to mention natural array computations Real-time programming Data-flow - a coherent way of treating data as the main object of interest, fundamental, yet a near-unique programming paradigm with many advantages and all integrated into a single programming environment where all the compilation and optimization is handled under the hood (with almost enough ability to tweak that) Unfortunately NI appear to be backing away from many of these strengths, and other features have been vastly overtaken (image processing has hardly been developed in the last 10 years, GUI design got sidetracked into NXG unfortunately). But the combination of low-level control in a very high-level language seems far too powerful and useful to have no future at all.6 points
-
Why are so many things just that little bit harder in or weirder in NXG? I am trying to use it to make my first "real" application, in this case a relatively simple WebVI. I put this list down in the hope someone can tell me I am being dumb and there is a sensible way to do these thing Why can I not easily branch off a wire by clicking on it somewhere? Now I have to right click and select the option to create a wire branch Why can I not right click on a primitive to open the sub-palette for that thing to give me similar items. I can right click and replace or right-click and insert... Example, I have an existing 2D array wire I want to get the size of, there is no way for me to right click the wire to quickly open the array palette and then drop down a Size primitive I have to relearn the whole palette structure as all the icons have changed. OK that is fine so let me explore a bit and poke around but I cannot keep a palette open by pinning it? (OK so it turns out I can do this if I start the browse from the left-hand palette and then weirdly click the << arrow, but I am so used to opening the palette by right clicking on the diagram). Arg, then the pop-up help covers over the next item in the list 😞 The Align menu is so much less usable in that drab gray and single line. There was nothing wrong with the way it is implemented in Current Gen, why change this? The GUI is so dull in general. The colours are washed out and grey everywhere is just depressing. It sounds silly but it makes me not want to use it. Sorry, but MDI is not a suitable technique for anything other than the most trivial of applications. I like the really like the zoom but please let us pan with the middle-mouse or something similar Please pop open menu items as soon as I browse into them, rather than forcing me to click (looking at you Case Structure Cases and Align menus) Why are the icons so confusing. Please can someone explain how the picture below conveys any information that this array concatenation. Why can I not run a Sub VI in a WebVI? In order to test the correctness of a piece of code I have to move it out of the .gcomp to run in isolation, and this actually moves the code on disk What was fundamentally wrong with the Project Window in Current Gen? I have a vertical monitor that I use exclusively for displaying the Project window and it is amazing. I don't particularly like the new implementation but at least let me undock it! I am also not really filled with confidence that as my project grows in size it will not become overwhelming (yet another reason to keep Virtual Folders) This is just a small subset of the items I am currently struggling with. In general I am quite forgiving of new software, but I think NXG has been baking in the oven for something like 8 years! I appreciate that NXG has not been designed for me, rather I suspect it is targeted at a whole new audience of LabVIEW developer. As such I know my muscle memory is going to be really detrimental in getting me up to speed with this new way of doing things so I am trying really hard to not let that get in the way of my journey. Something deep down just makes me worry that the essence of what makes LabVIEW (current gen) so special has been lost in translation. It just feels like too many decisions have been made by people who are not actually very familiar with LabVIEW. This makes me a bit sad as I have no doubt that a ridiculous amount of engineering effort and love has gone into NXG (and am under no illusions at the scale of the task of rewriting current gen). All in all my experience trying to develop a non trivial (not by much though) application in NXG has further cemented my thoughts that I am going to have to stick with current gen for the foreseeable future. That said, strength and courage to NI. I will check back again in a few years. ps: I am really excited for the WebVI technology. Please port it to Current Gen so I can actually use it 🙂
6 points
-
Thanks AQ, you are the first to actually spell this out in words that make sense to engineers. Not sure too many here are going to like it though! ps: I liked your post due to its honesty and absence of marketing weasel words, not because I think this is a particularly good strategy for NI. Maybe I have just had a weird career but in the 20 years or so I have been developing LabVIEW based solutions virtually never would a custom off-the-shelf piece of software like Signal Express or similar come anywhere close to doing what I needed it to and it would require so much customisation that the benefit would be so low. To me LabVIEW is a programming language or RAD tool and the responsibility of NI is to deliver first class hardware with amazing software to help me bring the two together and that is it.6 points
-
I don't mind the new green on the landing page of ni.com, but elsewhere on the site the new theme is a bit too much. I wanted to fix the near invisible links that @LogMAN ran into, but got a bit carried away: If anyone is interested in using the blue style, you can download it from here. Be warned it's not perfect, there's still lots of green bits on mouse over etc, but I find overall it makes the site much more readable. If blue isn't your thing, the primary color can be changed by setting the root --forrest-green color to something else.
6 points
-
The more I look at the center logo, the more I believe it captures exactly the kind of excitement generated by the whole operation.6 points
-
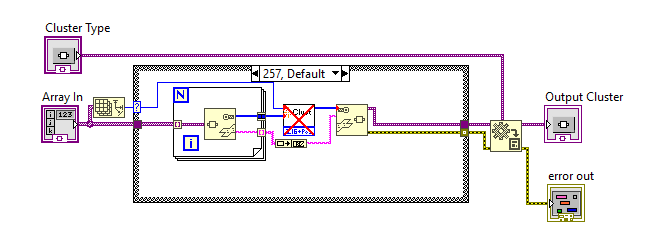
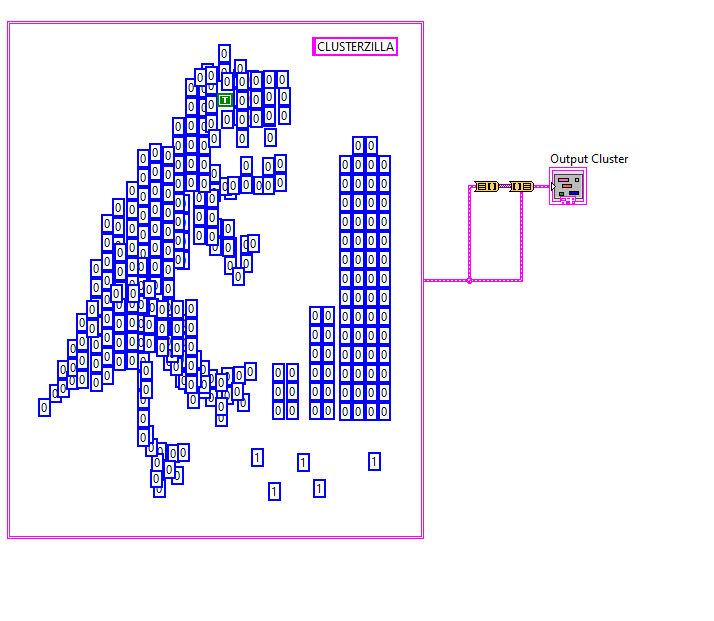
For a final Case. Sadly there isn't any non-depreciated Items to replace that vi. Which makes this work for Clusterzilla. ArrayToCluster.vim
6 points
-
All of the presentations are now on the LabVIEW Wiki. You can find them at: https://labviewwiki.org/wiki/Americas_CLA_Summit_2019 Thanks Kevin Shirey and Mark Balla for producing the videos and all those that volunteered to run the cameras. This is an awesome resource to be able to go re-watch and review these great presentations again or for those that couldn't join us in person to be able to view them as well.6 points
-
@Jim Kring, it seems to me that the export of the code has gotten a positive response from the community. However I may be wrong. If anyone has any opinion either way, please come forward. As you can see in this thread, it appears the community has rallied around this effort. This is why I emailed you to come here and share your thoughts. In the past, OpenG was a great venue to showcase how a bunch of passionate LabVIEW users can come together and collaborate on something useful. The passion is clearly still there, as shown by the numerous discussions here. The general coding community has moved to Git with GiHub being the hub. This seems like the logical next step. Who knows what this initiative will lead to. However, I’m expecting that placing OpenG in a neutral GitHub repo will provide the spark and the tools to facilitate open collaboration, then the community can drive the future. The community is full of smart people who have a desire for clean tested code. And if issues come up, LAVA discussions (or GitHub issues) are there to hash things out. When LAVA offered to host all OpenG discussions back in 2011. it was clear that the community wanted to help. When @jgcode put his standards together for how code should be discussed at that time, It was an exciting time. Since then, many people have come forward with offers to add new code into OpenG and fix bugs. For example @drjdpowell first offered to include his awesome SQLite toolkit for inclusion into OpenG. He got no response either way. It’s a shame to have a platform and forums to allow people to post and discuss OpenG code and then ignore it. If you have ideas on what the future of OpenG is. I’m hoping it’s to be more transparent and inclusive. Providing the tools, resources and some safety checks along the way, is the best way to facilitate passionate individuals to dive in. Do you think keeping the status quo of the past 10 years makes sense? It seems to me that the community disagrees. What do you think?6 points
-
You people are so laid back and forgiving. I’m an editor on multiple wikis across cyberspace, and none of the others are anything less than draconian. Capitalization whatever?! Wow. I’m going to need to wear my oversized Hawaiian shirt and cargo shorts when I’m editing, just to get in the right state of mind! 🙂6 points
-
6 points
-
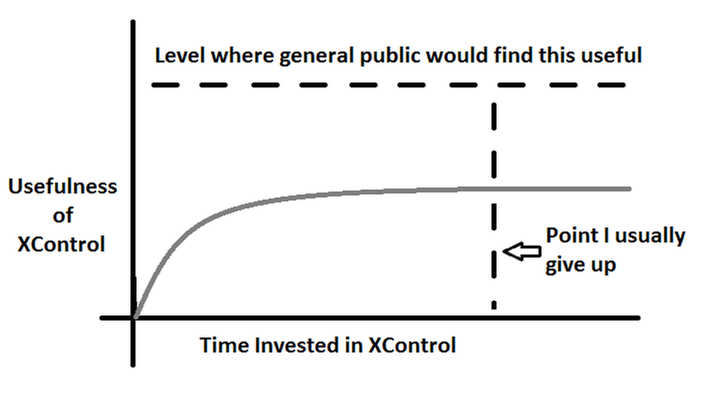
I just started down the rabbit hole of making a new XControl recently. Oh man such a pain. Here is a little graph I made complaining about the XControl creation process, and the time needed to make something useful. Any alternative is appreciated.
6 points
-
Version 1.0.0
475 downloads
There it is. The complete library for the MCP2221A. I2c adapter, I/O in a single IC. I love that one. Let me know if any bug is found. I try to make that library as much convenient as possible to use. Two version available 32 bit and 64 bit. little note: to open by serial number, the enumeration need to be activated on the device first. (open by index, enable the enumeration) It needs to be done only once in the life time of the device. PLEASE do not take ownership of this work since it is not yours. You have it for free, but the credit is still mine... I spent many hours of my life to make it works.6 points -
Version 1.0.0
1,052 downloads
Hi everyone, Since GRBL standard is open source, I decided to post my Library that I used in LabVIEW to interface a standard GRBL version 1.1 controller. Not all GRBL function has been integrated, but this is a very good start. Enjoy and let me know your comments. Benoit6 points -
Door Prize! Two of these custom bluetooth speakers will be given away, sponsored by the LAVA BBQ itself! [Front and back views]
6 points